What is the DOM
The DOM (Document Object Model) is a programming interface for web documents.
- Programming interface means API.
- Web document mean web page. web page is document.
The DOM represents the document with a logical tree. Each branch of the tree ends in a node, and each node contains objects. That way, programming languages, e.g. JavaScrpt, can interact with the document, can change the document structure, style, and content. Nodes can have event handlers attached to them. Once an event is triggered, the event handlers get executed.
DOM tree
A DOM tree is a tree structure whose nodes represent an HTML or XML document’s contents.
NOTE
Each HTML or XML document has a DOM tree representation.
When a web browser parses an HTML document, it builds a DOM tree and then uses it to display the document.
Example:
<html lang="en">
<head>
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
It has a DOM tree that looks like this:
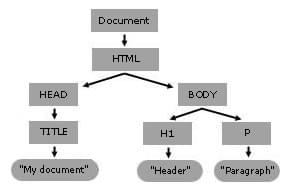
DOM API
The DOM API, also sometimes called the Document API, allows you to modify a DOM tree in any way you want.
DOM API including:
- core DOM: defines the entities describing any document and the objects within it. For example,
document,windoware most popular interfaces to access page. - HTML DOM API: adds support for representing HTML documents to the core DOM,
- SVG API: adds support for representing SVG documents.
The Terminology
DOM and HTML source code
It seems that HTML source code and the DOM are the same thing. But They are different. You can regard web page represented by the DOM tree. DOM tree conposite with HTML, CSS, JavaScript, etc. And DOM is the thing who implement DOM tree.
Let’s make an example: When you use a web browser to request a page like https://example.com the server returns HTML like this:
<!doctype html>
<html>
<head>
<title>Hello, world!</title>
</head>
<body>
<h1>Hello, world!</h1>
<p>This is a hypertext document on the World Wide Web.</p>
<script src="/script.js" async></script>
</body>
</html>
The browser parses the HTML and creates a tree of objects like this:
html
head
title
body
h1
p
script
This tree of objects, or nodes, representing the page’s content is called the DOM. Right now it looks the same as the HTML, but suppose that the script referenced at the bottom of the HTML runs this code:
const h1 = document.querySelector('h1');
h1.parentElement.removeChild(h1);
const p = document.createElement('p');
p.textContent = 'Wildcard!';
document.body.appendChild(p);
That code removes the h1 node and adds another p node to the DOM. The complete DOM now looks like this:
html
head
title
body
p
script
p
The page’s HTML is now different than its DOM. In other words, HTML represents initial page content, and the DOM represents current page content. When JavaScript adds, removes, or edits nodes, the DOM becomes different than the HTML.
DOM and JavaScript
DOM is not a language, you can say it is interface for language, like JavaScript, which want to interact with the page. The DOM is not part of the JavaScript language, but is instead a Web API used to build webpage.
NOTE
JavaScript is a language, DOM is the entity which are really accessing the page. And you use the language to access DOM so that you can control the document and its elements.
DOM and Node
All items in the DOM are defined as nodes. There are many types of nodes, but there are three main ones that we work with most often:
- Element nodes
- Text nodes
- Comment nodes
When an HTML element is an item in the DOM, it is referred to as an element node. Any lone text outside of an element is a text node, and an HTML comment is a comment node. In addition to these three node types, the document itself is a document node, which is the root of all other nodes.
Every node in a document has a node type, which can be accessed through the nodeType property.
Below is a chart of the most common node types:
| Node | Type Value | Example |
|---|---|---|
ELEMENT_NODE | 1 | The <body> element |
TEXT_NODE | 3 | Text that is not part of an element |
COMMENT_NODE | 8 | <!-- an HTML comment --> |
DOM and HTML element.
<a href="index.html">Home</a>
Here we have an anchor element, which is a link to index.html.
-
ais the tag -
hrefis the attribute -
index.htmlis the attribute value -
Homeis the text. Everything between the opening and closing tag combined make the entire HTML element. The simplest way to access an element with JavaScript is by theidattribute, using thegetElementById()method.
DOM and Event
Every Node support specific events and can have event handlers attached to their events. Once an event is triggered, the event handlers get executed.
DOM and Browser
Browser the software which implement DOM, run JavaScript, display page.
DOM and Document
- DOM is Document Object Model.
- The DOM API, also sometimes called the Document API.
The Document also refer to Document interface. The Document interface represents any web page loaded in the browser and serves as an entry point into the web page’s content, which is the DOM tree.
The Document interface describes the common properties and methods for any kind of document. Depending on the document’s type (e.g. HTML, XML, SVG, …), a larger API is available: HTML documents, served with the “text/html” content type, also implement the HTMLDocument interface, whereas XML and SVG documents implement the XMLDocument interface.
Virtual DOM and Shadow DOM
In short, the Shadow DOM is a browser technology whose main objective is to provide encapsulation when creating elements. On the other hand, the Virtual DOM is managed by JavaScript libraries—e.g., React and it’s mostly a strategy to optimize performance.
Virtual DOM
- VueJS and ReactJS both use Virtual DOM.
- Virtual DOM, in simple terms, is nothing but the complete and full representation of an actual DOM.
- Since any changes to the DOM cause the page to re-render more often than not, Virtual DOM primarily attempts to avoid any unnecessary and expensive changes to the DOM.
- It make following action easier: grouping changes and doing a single re-render instead of several small ones.
- A copy of the DOM is saved in the memory and is used to compare any changes being done anywhere in the DOM, it’s compared to find differences. Thus, only those parts of the application are re-rendered which are updated instead of re-rendering the entire DOM.
Shadow DOM
- Shadow DOM, on the other hand, relates mostly to the concept of encapsulation. It is a tool that allows developers to overcome DOM encapsulation.
- It refers to the browser’s potential to add a subtree of DOM elements into the rendering of a document, but not into the DOM tree of the main document.
- Thus, it isolates the DOM and ensures that the DOM of a component is a separate element that won’t appear in a global DOM.
- Contrary to the DOM, Shadow DOM occurs in smaller pieces, implying that (unlike the Virtual DOM) it is not a complete representation of the entire DOM.
- It is also proven to be helpful with CSS scoping. The styles used in an application can overlap which makes it cumbersome to handle them. Shadow DOM ensures that the styles created inside a single Shadow DOM element remain isolated and within their own scope.
HTMLCollection vs NodeList
When traversing the DOM sometimes you will get returned a collection of elements/nodes (querySelector, children). This will either be an HTMLCollection or a NodeList.
-
An HTMLCollection is pretty simple to understand since it can only contain elements. Methods such as
getElementsByClassNameandchildrenreturn an HTMLCollection. These collections are very similar to arrays, but Things like forEach, map, and reduce are not available on an HTMLCollection. Also, HTMLCollections are live updating. This means that if you have an HTMLCollection of all elements with the class active and you add a new element to the DOM with that class it will automatically be added to the HTMLCollection. This is honestly a bit of a pain to deal with as it can cause unexpected bugs. -
A NodeList on the other hand can contain any type of node including elements. NodeLists are also similar to arrays, but they again lack most higher order functions. The only higher order function on a NodeList is the forEach function. Some examples of methods that return NodeLists are
querySelectorAllandchildNodes. NodeLists are also live updating similar to HTMLCollections, but only in some cases. For example, querySelectorAll is not a live updating list, but childNodes is live updating.
Generally, I try to avoid NodeLists since they can contain non-HTML elements, but querySelectorAll will only ever return elements inside the NodeList so I use querySelectorAll constantly.
In general I prefer working with elements inside a NodeList whenever possible as they are the easiest to work with in my opinion.
Conclusion
In many situation, DOM is referred to as the DOM tree. But DOM tree just part of DOM. DOM also include the interfaces which are used to interact with DOM tree.