Computer just deal with bytes! When communicating with computer, we need code encoding. There are hundreds of code exist. The first and popular one is ASCII. And the last one and final one should be Unicode.
Here is glossary: ASCII (/ˈæskiː/) (American Standard Code for Information Interchange) Unicode (Universal Coded Character Set) UTF-8 (Unicode Transformation Format - 8-bit) UTF-16 (Unicode Transformation Format - 16-bit) BMP (Basic Multilingual Plane) BOM (byte-order mark)
ASCII
ASCII is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Originally based on the English alphabet, ASCII encodes 128 specified characters into seven-bit integers.

Unicode
Unicode is an attempt to define every possible human character and assign it a number. This number is called a codepoint.
- Unicode is the standard that defines the codepoint.
- Unicode defines 144,697 characters covering 159 modern and historic scripts, as well as symbols, emoji, and non-visual control and formatting codes.
Unicode and UCS
Unicode and the ISO’s Universal Coded Character Set (UCS) use identical character names and code points. However, the Unicode versions do differ from their ISO equivalents in two significant ways.
- While the UCS is a simple character map, Unicode specifies the rules, algorithms, and properties necessary to achieve interoperability between different platforms and languages.
- the frequency with which updated versions are released and new characters added.
What is Planes
The Unicode codespace is divided into seventeen planes, numbered 0 to 16. Plane 0: Basic Multilingual Plane. Plane 1 - 7: Supplementary planes.
All code points in the BMP are accessed as a single code unit in UTF-16 encoding and can be encoded in one, two or three bytes in UTF-8.
Unicode encoding
A Unicode string is a sequence of code points, which are numbers from 0 through 0x10FFFF (1,114,111 decimal). This sequence of code points needs to be represented in memory as a set of code units, and code units are then mapped to 8-bit bytes. The rules for translating a Unicode string into a sequence of bytes are called a character encoding, or just an encoding.
In brief, encoding is the rule which translate code points to code units.
- In UTF-8 a character might be encoded with one byte, two bytes, three bytes, or four bytes.
- UTF-8 is popular at web. UTF-16 is popular at Windows, programming language. UTF-32 is too big. UCS2 is still be used, but have been obsolete.
Why there are many encoding to represent Unicode code point?
Because we have different purposes, so we need different encoding. For example, in ASCII, the code of ‘A’ is ‘065’, byte is ‘01000001’. it looks obviously. But Unicode is bigger, complicated and keep updating. For example, The code of ‘A’ is ‘U+0041, the code of ‘𠜎’ is ‘U+2070E’. Simple solution is UTF-32. But UTF-32 have it’s shortcoming. like space, byte ordering. The UTF-8 encode ASCII letter as one byte and same value with Unicode code point. The UTF-16 encode BMP plane as two bytes and same value with Unicode code point. But others code points will be following different rules depends on the encoding.
We need to consider some situation: • bytes are corrupted or lost. • portable between different processors which byte-ordering can be different. • The size of space. • compatible with existing C functions
UTF-8
The name of UTF-8 is confusing. Actually UTF-8 is a variable-width character encoding used for electronic communication. UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one-byte (8-bit) code units. UTF-8 is by far the most common encoding for the World Wide Web. UTF-8 is defacto standard encoding.
UTF-8 uses the following rules:
- If the code point is < 128, it’s represented by the corresponding byte value. It is backward compatibility with ASCII.
- If the code point is >= 128, it’s turned into a sequence of two, three, or four bytes, where each byte of the sequence is between 128 and 255.
How UTF-8 works
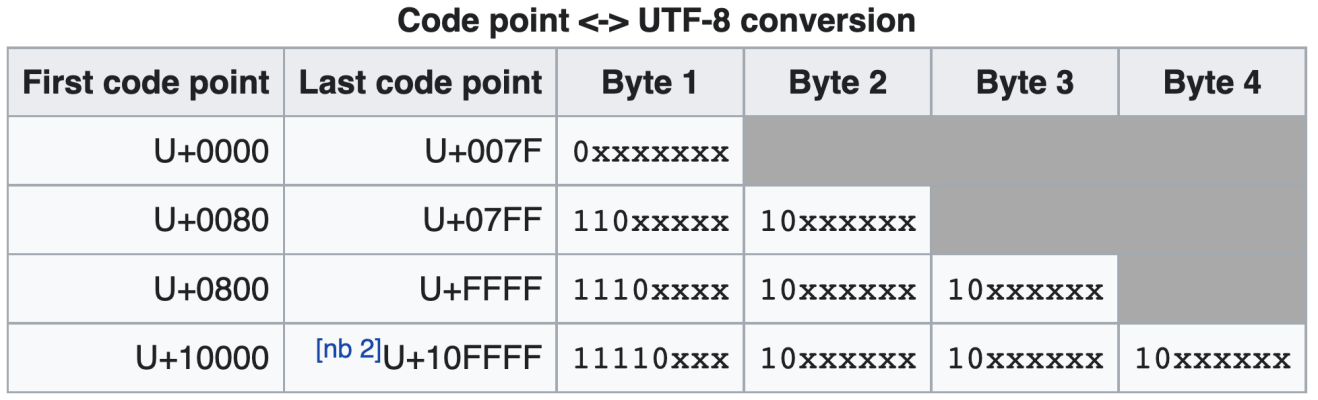
UTF-8 has several convenient properties:
- It can handle any Unicode code point.
- A Unicode string is turned into a sequence of bytes that contains embedded zero bytes only where they represent the null character (U+0000). This means that UTF-8 strings can be processed by C functions such as strcpy() and sent through protocols that can’t handle zero bytes for anything other than end-of-string markers.
- A string of ASCII text is also valid UTF-8 text.
- UTF-8 is fairly compact; the majority of commonly used characters can be represented with one or two bytes.
- If bytes are corrupted or lost, it’s possible to determine the start of the next UTF-8-encoded code point and resynchronize. It’s also unlikely that random 8-bit data will look like valid UTF-8.
- UTF-8 is a byte oriented encoding. The encoding specifies that each character is represented by a specific sequence of one or more bytes. This avoids the byte-ordering issues that can occur with integer and word oriented encodings, like UTF-16 and UTF-32, where the sequence of bytes varies depending on the hardware on which the string was encoded.
UTF-16
UTF-16 is another character encoding which also is capable of encoding all 1,112,064 valid character code points of Unicode. The encoding is variable-width, as code points are encoded with one or two 16-bit code units.
-
UCS-2 is a precursor of UTF-16 without full support for Unicode, it have been obsolete. It uses two bytes (16 bits) for each character but can only encode the first 65,536 code points, the so-called Basic Multilingual Plane (BMP).
-
UTF-16 extends UCS-2, by using the same 16-bit encoding as UCS-2 for the Basic Multilingual Plane, and a 4-byte encoding for the other planes.
How UTF-16 work
Each Unicode code point is encoded either as one or two 16-bit code units. How these 16-bit codes are stored as bytes then depends on the ‘endianness’ of the text file or communication protocol.
-
Code points from U+0000 to U+D7FF and U+E000 to U+FFFF These code points is the Basic Multilingual Plane (BMP). UTF-16 encode code points in this range as single 16-bit code units that are numerically equal to the corresponding code points.
-
Code points From U+D800 to U+DFFF The Unicode standard permanently reserves these code point values for UTF-16 encoding of the high and low surrogates, and they will never be assigned a character.
-
Code points from U+010000 to U+10FFFF Code points from the other planes (called Supplementary Planes) are encoded as two 16-bit code units called a surrogate pair, by the following scheme:
• 0x10000 is subtracted from the code point (U), leaving a 20-bit number (U’) in the hex number range 0x00000–0xFFFFF. Note for these purposes, U is defined to be no greater than 0x10FFFF. • The high ten bits (in the range 0x000–0x3FF) are added to 0xD800 to give the first 16-bit code unit or high surrogate (W1), which will be in the range 0xD800–0xDBFF. • The low ten bits (also in the range 0x000–0x3FF) are added to 0xDC00 to give the second 16-bit code unit or low surrogate (W2), which will be in the range 0xDC00–0xDFFF.
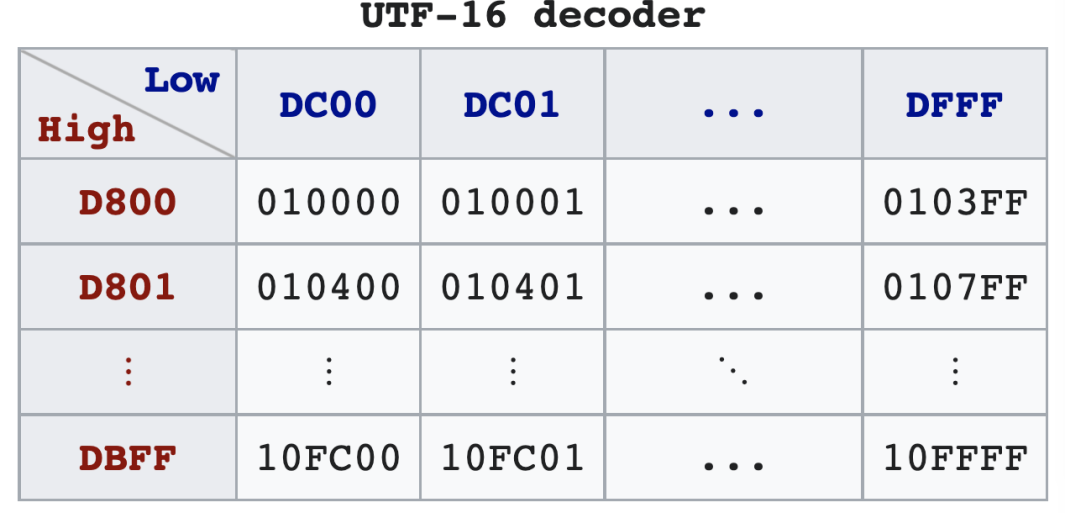
Illustrated visually, the distribution of U’ between W1 and W2 looks like:
U' = yyyyyyyyyyxxxxxxxxxx // U - 0x10000
W1 = 110110yyyyyyyyyy // 0xD800 + yyyyyyyyyy
W2 = 110111xxxxxxxxxx // 0xDC00 + xxxxxxxxxx
UTF-8 vs. UTF-16
-
They are not compatible with each other.
-
UTF-8 encodes a character into a binary string of one, two, three, or four bytes. UTF-16 encodes a Unicode character into a string of either two or four bytes.
-
UTF-8 encoding is much popular than UTF-16 on the web, maybe because it uses less memory. UTF-8 accounts for 98% of all web pages. WHATWG considers UTF-8 “the mandatory encoding for all text” and that for security reasons browser applications should not use UTF-16.
-
UTF-16 is used by systems such as the Microsoft Windows API, the Java programming language and JavaScript. Since May 2019, Microsoft has begun supporting UTF-8 (as well as UTF-16) and encouraging its use.
-
UTF-16 is used by SMS.
-
UTF-16 need to use Unicode character U+FEFF as a byte-order mark (BOM) identify the byte ordering. UTF-8 don’t care byte ordering.
Questions about encoding
What is UTF-16 high surrogate, UTF-16 low surrogate?
High low Surrogate are the ways using which UTF-16 encode Unicode code point in Supplementary Planes
How about other encoding
- UTF-32 is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point.
- GB18030
What is glyph
A character is represented on a screen or on paper by a set of graphical elements that’s called a glyph.
Why UTF-8 don’t care the byte order issue? What is byte oriented encoding?
Because there are marks on each byte in UTF-8 encoding. According to these marks, we can infer the byte ordering.
reference
https://nedbatchelder.com/text/unipain.html