Textual data in Python is handled with str objects, or call strings. Strings are immutable sequences of Unicode code points.
- Like JavaScript, strings in Python are arrays of bytes representing unicode characters.
- Square brackets can be used to access elements of the string.
- You can loop through a string.
- Using
len()to get length of a string. - Support keyword in, not in.
- Python doesn’t have character type, a single character is simply a string with a length of 1.
- You can assign a multiline string to a variable by using three quotes.
- Python has a set of built-in methods that you can use on strings.
Basic Operation
String slice syntax
string slice is a convenient way to operate string.
b = "Hello, World!"
b[2] #"l"
b[2:5] #"llo"
b[::-1] #reverse a string: "!dlroW ,olleH"
split string
a = "Hello, World!"
print(a.split(",")) # ['Hello', ' World!']
join string
opposite of split(), joins the elements in the given list together.
a = ['Hello', ' World!']
print(",".join(a)) # "Hello, World!"
replace
a = "Hello, World!"
print(a.replace("H", "J")) # "Jello, World!"
find() and rfind()
find() return the index of the first location. rfine() return the index of last one.
s.lower(), s.upper()
returns the lowercase or uppercase version of the string
translate()
The translate() method returns a string where some specified characters are replaced with the character described in a dictionary, or in a mapping table.
- Use the str.maketrans() method to create a mapping table.
str Object
class str(object='')
class str(object=b'', encoding='utf-8', errors='strict')
Return a string version of object. If object is not provided, returns the empty string. Otherwise, the behavior of str() depends on whether encoding or errors is given.
print("20 days are " + str(20*24*60*60) +" seconds")
String module
string module is a built-in module and we have to import it before using any of its constants and classes. Because str class, String module have been old. and you should not use.
String format
There are several way to format, manipulate string:
- printf-style, template, str.format() have been old style way.
- f-string is the latest way and recommend use.
printf-style String Formatting (old sytle)
String objects have one unique built-in operation: the % operator (modulo). The effect is similar to using the sprintf() in the C language. Example:
print('%(language)s has %(number)03d quote types.' %
{'language': "Python", "number": 2})
// Python has 002 quote types.
def dec2hexstring(dec):
decimal = int(dec)
hexa = '%#X' % decimal
return hexa
But recommend to use the newer formatted string literals, the str.format() interface, or template strings. f-String is latest way to format string!
str.format(*args, **kwargs)
Perform a string formatting operation. (Format string means create string, make string.) The string on which this method is called can contain literal text or replacement fields delimited by braces {}.
- Introduced in Python 2.6.
- str.format(), when deal with multiple arguments, and long strings. it will looks verbose.
"The sum of 1 + 2 is {0}".format(1+2) get 'The sum of 1 + 2 is 3'
'{2}, {1}, {0}'.format('a', 'b', 'c') get 'c, b, a'
Format String Syntax:
replacement_field ::= "{" [field_name] ["!" conversion] [":" format_spec] "}"
field_name can be 0, 1, 2… which is positional of the parameters. or be nothing, which still positional. or be key name of the dic which is the parameter. or be attribute of object which is the parameter.
conversion have three options: !s, !r, !a "repr() shows quotes: {!r}; str() doesn't: {!s}".format('test1', 'test2') get "repr() shows quotes: 'test1'; str() doesn't: test2"
format_spec is a Mini-Languag! Start from ‘:’. For example display in Hexadecimal, or octal, binary. It can do more, specify the type, fill, align, width, precision :
>>> for align, text in zip('<^>', ['left', 'center', 'right']):
... '{0:{fill}{align}16}'.format(text, fill=align, align=align)
...
'left<<<<<<<<<<<<'
'^^^^^center^^^^^'
'>>>>>>>>>>>right'
Using the comma as a thousands separator:
>>> '{:,}'.format(1234567890)
'1,234,567,890'
Nesting arguments:
for align, text in zip('<^>', ['left', 'center', 'right']):
print('{:{fill}{align}30}'.format(text, fill=align, align=align))
Template strings
Template strings is very simple string formatting tool which focus on substitutions.
A primary use case for template strings is for internationalization (i18n) since in that context, the simpler syntax and functionality makes it easier to translate than other built-in string formatting facilities in Python. The string module provides a Template class that implements these rules. Main methods is substitute(), and safe_substitute()
from string import Template
s = Template('$who likes $what')
s1 = s.substitute(who='tim', what='kung pao')
print(s1) #'tim likes kung pao'
formatted string literal / f-Strings (Python 3.6+ new syntax)
- (f-String are similar to JavaScript’s Template Literal)
- A formatted string literal or f-string is a string literal that is prefixed with ‘f’ or ‘F’.
- These strings may contain replacement fields, which are expressions delimited by curly braces {}.
- While other string literals always have a constant value, formatted strings are really expressions evaluated at run time.
- f-strings are a great new way to format strings. Not only are they more readable, more concise, and less prone to error than other ways of formatting, but they are also faster!
- format syntax is similar to str.format()
>>> name = "Fred"
>>> f"He said his name is {name!r}."
"He said his name is 'Fred'."
>>> f"He said his name is {name}."
"He said his name is Fred."
>>> number = 1024
>>> f"{number:#0x}" # using integer format specifier
'0x400'
- Support triple quote mark. So it is easy to support Multiline f-Strings
- f-string support function
>>> def to_lowercase(input):
... return input.lower()
>>> name = "Eric Idle"
>>> f"{to_lowercase(name)} is funny."
'eric idle is funny.'
Unicode Support
Great presentation about Unicode: https://nedbatchelder.com/text/unipain.html
Overview
Strings can either be represented in bytes or unicode code points. Byte strings and unicode strings each have a method to convert it to the other type of string.
unicode .encode() → bytes
bytes .decode() → unicode
In Python 2, a string is by default a binary string and you need to use u’’ to mark a string as a Unicode string. If you try to perform a string operation that combines a unicode string with a byte string, Python 2 try to be helpful, it will implicitly decode the byte string to produce a second unicode string, then complete the operation. But the conversion from int to float can’t fail, while byte string to unicode string can.
In Python 3, a string by default is a Unicode string (You don’t need to know HOW Python deal with it), and you need to use b’’ to explicitly mark a string as a binary string. bytes and str are different types. In Python3, they are not converted to each other implicitly. You need to handle both types by yourself.
The default encoding for Python source code is UTF-8, so you can simply include a Unicode character (or use u escape) in a string literal:
print("Fichier non trouvé")
>>> "\u0394" # Using a 16-bit hex value
'\u0394'
Python 3 also supports using Unicode characters in identifiers. (JavaScript support as well)
Unicode Sandwich theory

A good practice is to decode your bytes in UTF-8 (or an encoder that was used to create those bytes) as soon as they are loaded from a file. Run your processing on unicode code points through your Python code, and then write back into bytes into a file using UTF-8 encoder in the end.
Python3 handles Unicode strings with unicode code points. You don’t need to know HOW. This is the job of Python 3. You can just take it as a black box. Python3 make sure you can use all the methods of str type. Just remember the Sandwich mode! What you need to handle is decode as soon as possible, and encode at the end.
5 fact of life about unicode string in Python
-
everything in a computer is bytes. Files on disk are a series of bytes, and network connections only transmit bytes.
-
The world needs more than 256 symbols
- Bytes and Unicode, Need to keep them straight, Need to deal with both.
- You can’t pretend that everything is bytes, or everything is unicode. You need to use each for their purpose, and explicitly convert between them as needed.
- So Python 2’s pain is deferred: you think your program is correct, and find out later that it fails with exotic characters.
- With Python 3, your code fails immediately, so even if you are only handling ASCII, you have to explicitly deal with the difference between bytes and unicode.
-
Encoding is out-of-band. You cannot infer the encoding of bytes. You must be told, or you have to guess.
- Data is dirty. Sometimes you are told wrong.
3 Pro tips
- Unicode Sandwich
- Know what you have! Bytes or Unicode? If bytes, what encoding?
- Test Unicode
Reading files
In Python 3, the two modes produce different results. When you open a file in text mode, either with “r”, or by defaulting the mode entirely, the data read from the file is implicitly decoded into Unicode, and you get str objects. If you open a file in binary mode, by supplying “rb” as the mode, then the data read from the file is bytes, with no processing done on them.
>>> open("hello.txt", "r").read()
'Hello, world!\n'
>>> open("hello.txt", "rb").read()
b'Hello, world!\n'
To get the file read properly, you should specify an encoding to use. The open() function now has an optional encoding parameter.
>>> open("hi_utf8.txt", "r", encoding="utf-8").read()
'Hi \u2119\u01b4\u2602\u210c\xf8\u1f24'
>>> open("hi_utf8.txt", "r").read() # wrong encoding
'Hi \xe2\u201e\u2122\xc6\xb4\xe2\u02dc\u201a\xe2\u201e\u0152\xc3\xb8\xe1\xbc\xa4'
Internal representations for Unicode strings
Even the default encoding for Python source code is UTF-8. But for Unicode strings, Python uses three kinds of internal representations : 1 byte per char (Latin-1 encoding) 2 bytes per char (UCS-2 encoding) 4 bytes per char (UCS-4 encoding)
If all characters in a string can fit in ASCII range, then they are encoded using 1-byte Latin-1 encoding. But if there are any char which need two bytes, then Python will encoding all to UCS-2. same
This is because each character in a string must take up an equivalent number of bytes! otherwise, operations such as indexing, slicing would be inaccurate.
s0 = 'a'
print(sys.getsizeof(s0+'b') - sys.getsizeof(s0))
>1
s1 = '你'
print(sys.getsizeof(s1+'你') - sys.getsizeof(s1))
>2
print(sys.getsizeof(s1+'你a') - sys.getsizeof(s1))
>4
s1 = '🐍'
print(sys.getsizeof(s1+'🐍你') - sys.getsizeof(s1))
>8
Within CPython, unicode characters are stored as PyUnicodeObject instances. We can view the format of a PyUnicodeObject by looking at the source code:
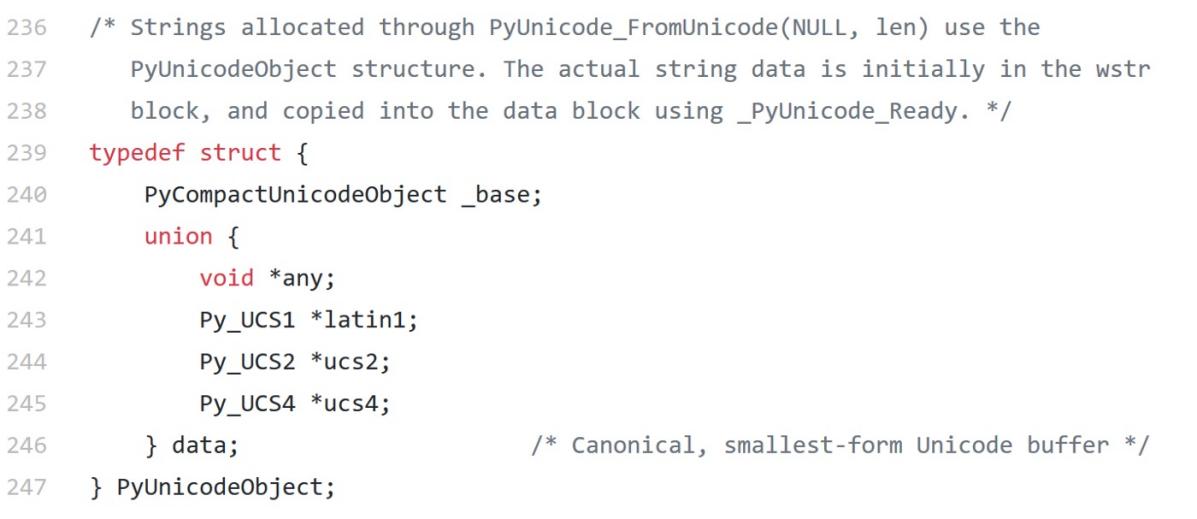
build-in function chr(), ord()
Convert between One-character Unicode strings and code point value. These tow functions do nothing about encoding.
chr()
takes code point value(integers) and returns a Unicode string of length 1 that contains the corresponding code point.
ord()
takes a one-character Unicode string and returns the code point value (integers).
# '\u0041' == 'A'
>>> chr(65)
'\u0041'
>>> ord('\u0041')
65
Unicode Literals in Python Source Code
In Python source code, specific Unicode code points can be written using the \u escape sequence, which is followed by four hex digits giving the code point. The \U escape sequence is similar, but expects eight hex digits, not four:
>>> s = "a\xac\u1234\u20ac\U00008000"
>>> [ord(c) for c in s]
[97, 172, 4660, 8364, 32768]
bytes.decode() and str.encode()
bytes.decode() can create a string.
This method takes an encoding argument, such as UTF-8, and optionally an errors argument. (\xNN escape sequence means that NN is Hexadecimal value)
>>> b'\x41'.decode("utf-8")
A
>>> b'\x41\x00'.decode("utf-16")
A
str.encode()
returns a bytes representation of the Unicode string, encoded in the requested encoding. (opposite method of bytes.decode())
>>> u = chr(65) + 'abcd' + chr(66)
>>> u.encode('utf-8')
b'AabcdB'
>>> u.encode('utf-16')
b'\xff\xfeA\x00a\x00b\x00c\x00d\x00B\x00'
- Unicode code point for emoji 🖐 is U+1F590
print(("你好🖐").encode("unicode_escape"))
b'\\u4f60\\u597d\\U0001f590'
print(("你好🖐").encode())
b'\xe4\xbd\xa0\xe5\xa5\xbd\xf0\x9f\x96\x90'
codecs module
The low-level routines for registering and accessing the available encodings are found in the codecs module. Implementing new encodings also requires understanding the codecs module.
Unicode in JavaScript
- While a JavaScript source file can have any kind of encoding, JavaScript will then convert it internally to UTF-16 before executing it.
- JavaScript strings are all UTF-16 sequences, as the ECMAScript standard says: When a String contains actual textual data, each element is considered to be a single UTF-16 code unit.
- UTF-16 encoding need to use with surrogate pairs. For the code points which bigger than U+FFFF.
- Example (use u escape):
console.log('the heart eyes emoji is \ud83d\ude0d')
//> the heart eyes emoji is 😍
Tips for Writing Unicode-aware Programs
- Software should only work with Unicode strings internally,
- decoding the input data as soon as possible and,
- encoding the output only at the end.
String interning
String interning is a method of storing only one copy of each distinct string value in memory, which must be immutable.
- String interning concept is akin to shared object concept! shared object is more popular in immutable object.
- String Interning can Saving Memory, Fast Comparisons, Fast Dictionary Lookups.
Implicit String interning
Implicitly intern string depends on several factors:
- All empty strings and strings of length 1 are interned.
- Up until version 3.7, Python used peephole optimization, and all strings longer than 20 characters were not interned. However, now it uses the AST optimizer, and (most) strings up to 4096 characters are interned.
- Names of functions, class, variables, arguments, etc. are implicitly interned.
- The keys of dictionaries used to hold module, class, or instance attributes are interned.
- Strings are interned only at compile-time, this means that they will not be interned if their value can’t be computed at compile-time.
s1 = 'iambenwen'
s2 = 'iambenwen'
print(s1 is s2)
>true
>>> "strin"+"g" is "string"
True
Python won’t intern all the string.
>>> c = 'Y'*4097
>>> d = 'Y'*4097
>>> c is d
false
s1 = "wen".join(["b", "e", "n"])
s2 = "wen".join(["b", "e", "n"])
print(s1 is s2)
>false
>>> s1 = "strin"
>>> s2 = "string"
>>> s1+"g" is s2
False
Don’t Rely on the Implicit String Interning
Because the rules of the implicit string interning could be different according to different compiler, interpreter. For example, up until the version of Python 3.7, the peephole optimization is used for string interning and all strings longer than 20 characters will not be interned. However, the algorithm was changed to the AST optimizer then, and the length is equal to 4096 rather than 20.
Explicit interning
>>> import sys
>>> c = sys.intern('Y'*4097)
>>> d = sys.intern('Y'*4097)
>>> c is d
True
In practice, we should use the == operator to compare strings. If we need to speed up the comparison, intern the strings explicitly.
Disadvantages of String Interning
- Memory Cost.
- Time Cost: The call to intern() function is expensive as it has to manage the interned table.
- not friendly for Multi-threaded Environments .
The following comparison returns True because of shared objects.
CPython loads the Latin-1 range of characters unicode decimals 0 to 255, inclusive, as shared objects every time Python is initialized. Any calls to values in this range are referred to those pre-existing objects.
s3 = 'levin'
s4 = 'elise'
print(s3[1] is s4[0])
#>true
String Questions
If using u escape sequence follow by code point can display Unicode string. why need encoding?
s = "\u0041\u1234\u20ac\u8000\U0002070E"
print([ord(c) for c in s]) # get unicode’s integer value:
#>[65, 4660, 8364, 32768, 132878]
print([chr(ord(i)) for i in s]) # get one-character string:
#>['A', 'ሴ', '€', '耀', '𠜎']
print(s.encode('utf-8').hex()) # get actually bytes of utf-8 encoding:
#>41e188b4e282ace88080f0a09c8e
print(s.encode('utf-16').hex()) # get utf-16
#>fffe41003412ac20008041d80edf
print(s.encode('utf-32').hex()) # get utf-32
#>fffe00004100000034120000ac200000008000000e070200
(The Unicode character U+FEFF is used as a byte-order mark (BOM), and is often written as the first character of a file in order to assist with auto detection of the file’s byte ordering. )
-
ONE important concept is that, in Python, only refer to store or transmit strings when talking about encodings.
- Using code point can display unicode string! utf-32 can be represented by codepoint totally. But this encoding have some shortcoming. like consuming too many space, byte ordering issue.
- Python say it represent string with code point internally. it is possible and it is good to support string methods. The encoding can be ASCII, or USC2, or USC4. But user can store or transmit string by UTF-8
How to change str encoding.
In Python, str type is Unicode string. str’s encoding just for store or transmission. str.encode() support around 100 encoding type.
How to know the encoding of one String? How do Python identify the encoding of one string?
Encoding is out-of-band. You cannot infer the encoding of bytes. You must be told, or you have to guess.
How to judge the string if we just get part of the string?
UTF-8 performing better at this issue.
How to indexing, slicing, getting length of a Unicode String?
Variable length encoding can make indexing slicing getting length fail. Python’s string type is using Unicode, but internal encoding is vary which depending on what characters the string contains.
What is the relationship between string interning and encoding?
Not relative